热迁移的基本原理,以及热迁移时kvm脏页的追踪情况
热迁移介绍
虚机迁移分成冷迁移和热迁移, 冷迁移是指虚机关机之后迁移,热迁移是虚机不停机迁移,对客户体验比较好,因此在云场景下使用最多。热迁移分成准备, 传输内存和磁盘,停机拷贝,目标机恢复运行几个阶段。
准备阶段
Step.1 选择一台具有足够磁盘和内存资源的物理机DestHost,并在DestHost上创建VM对应的系统盘和数据盘,同时选定接收迁移数据的tcp端口,这两个磁盘在DestHost和SourceHost上的路径必须完全一致。不同的是,DestHost上初始创建的只是空盘,上面没有真实数据。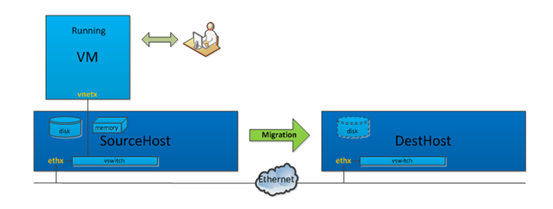
Step.2 通过虚拟化管理软件Libvirt在DestHost上创建一个和VM同样配置的虚拟机VM’,系统盘和数据盘使用Step.1中创建的系统盘和数据盘。VM’当前是paused状态,虚拟机VM’的vcpu处于暂停状态,同时虚拟机VM’会通过监听一个内网的tcp端口来接收迁移数据。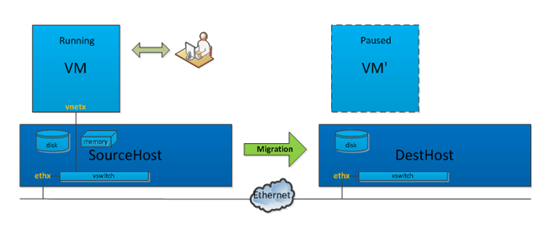
迁移阶段
Step.3 虚拟化管理层Libvirt给VM对应的Qemu进程发出一个迁移指令,并指定参数,例如指定DestHost为目标、需要迁移块设备、最大停机时间、迁移带宽限制等,然后迁移数据就会通过指定tcp链路传输给DestHost上的VM’。需要注意,迁移数据的网络包不是经过 vswitch,而是直接从SourceHost的ethx网卡出,进到DestHost的ethx,因为VM’对应Qemu进程正作为DestHost一个用户态进程,监听在ethx对应的内网ip。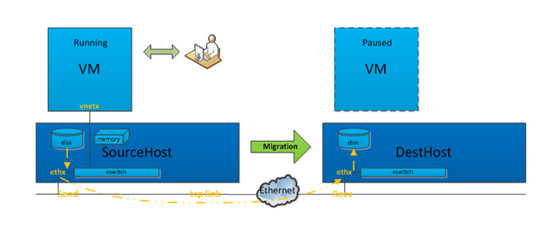
Step.4 经过前面三步,虚拟机的数据就正式开始迁移,剩下的挑战是如何保证数据迁移的一致性,因为此时VM处于运行状态,里面时刻发生内存更新、磁盘io操作和设备状态变更,而VM’是paused状态,只通过一个线程接收VM进程发过来的数据。
为此,在迁移过程中各种数据如何有序迁移?首先,Libvirt会发送qmp_dirve_mirror命令来通知Qemu进行虚拟机磁盘数据迁移,从而在源端和目标端直接同步磁盘数据。然后,Libvirt会再次发送qmp_migrate命令通知Qemu进行虚拟机内存数据迁移,进一步完成虚拟机主要数据的迁移。最后,由于设备状态对应的数据量很少,在迁移最后阶段会通过一次性同步,将Qemu里每个设备注册的状态同步到目标端。
另外,迁移过程中发生变更的数据如何迁移?如果不迁移变更的数据,那数据必然不一致,也表明迁移还不能结束,因此Qemu一般通过数据迁移准备、数据迁移、数据迁移收尾三个步骤来完成。
循环调用磁盘和内存迁移函数也是按阶段来分别调用的。首先,循环调用磁盘和内存迁移函数的迁移数据准备功能,即前期准备工作,例如把磁盘按block为单位组织成一个数组,并设置记录脏块机制;把内存所有页全部设置为脏页,并发送开始迁移的标志到VM’的进程。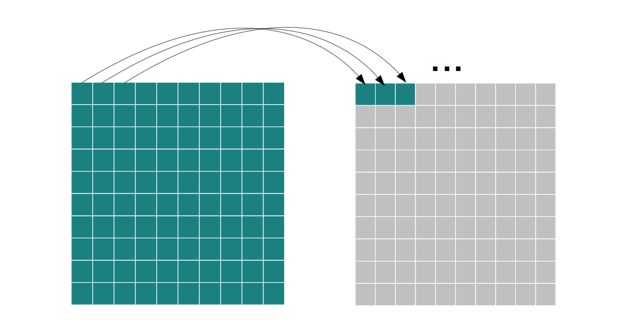
紧接着,需要进行真正的数据迁移,Qemu在这个阶段调用磁盘和内存迁移函数的第二步骤功能,并且要求必须等磁盘数据迁移完成后才会执行内存数据迁移。如图 1-4所示,Qemu首先会进行磁盘(内存)的全量数据迁移,依次将每个block(页)迁移到目标端DestHost。
然后再通过多次迭代,将迁移过程中虚拟机产生的新数据迁移到目标端DestHost。这一迭代过程是收敛的,收敛依据与之前设置的带宽、最大停机时间有关。同时,在迭代过程中,Qemu将边迁移边记录剩下的脏数据大小,并与停机时间进行比较,如果这个值比停机时间大,那么继续迁移,如果比停机时间小,那么源端Qemu进程就会暂停,从而避免产生新的脏数据,以便进行迁移收尾工作。
在虚拟机暂停之后,进入第三步迁移收尾工作,源端Qemu进程会把磁盘、内存脏数据和设备状态一次性同步到目标端,完成时VM和VM’的数据将会一致。这时,上层管理软件会把VM关闭,并把VM’的vcpu恢复运行状态,整个虚拟机的数据迁移就完成了。
切换阶段
Step.5 数据迁移完成后,VM关闭,VM’作为它的一个完全拷贝,在DestHost上运行着,但网络还是不通的。VM’通过DestHost的vswitch 连接到物理机网卡,vswitch相当于一个虚拟交换机,而VM从SourceHost迁移到DestHost,在网络上相当于把网线从一个交换机拔下插到另一个交换机上,此时就需要一次arp广播,告知VM的mac地址已经变更到另外一台交换机的某个端口。
这就是迁移完成后的网络切换,由于切换时间很短,少于tcp的超时重传时间,因此对于原VM上跑着网络服务程序几乎是无感知的。此后,如图 1-6所示,目标端DestHost虚拟机就具备和用户直接进行交互的能力,而源端SourceHost虚拟机此时就可以删除。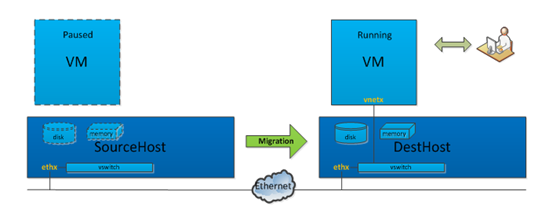
qemu-kvm 内存脏页追踪
qemu内存迁移工作流程
¢ 第一轮将所有guest ram pages迁移过去
¢ 每轮迭代开始前进行脏页同步
¢ 后续迭代只迁移脏页
¢ 最后一轮进行停机迁移
x86 page table entry 描述符
A(Access) - 当这个page被访问(读/写)过后,硬件将该位置1,TLB只会缓存access的值为1的page对应的映射关系。软件可将该位置0,然后对应的TLB将会被flush掉。
D (Dirty)- 这个标志位只对file backed的page有意义,对anonymous的page是没有意义的。当page被写入后,硬件将该位置1,表明该page的内容比外部disk/flash对应部分要新,当系统内存不足,要将该page回收的时候,需首先将其内容flush到外部存储。之后软件将该标志位清0。
Intel page modification logging (PML) 硬件特性追踪脏页,具体步骤
a. 当CPU想要记录内存脏页,比如迁移开始时,首先设置Accessed and Dirty flags和PML flag标志,使能脏页记录功能。当CPU写VM的物理内存页时,如果发现Accessed and Dirty和PML都使能了,会首先将对应表项的Access和Dirty位置1,然后将GPA记录到PML Buffer中。每写一次物理内存页,PML Buffer就多一条GPA的记录,PML index减1。
b. 当PML Buffer被填满时,会产生page-modification log-full event,然后触发VMExit。
c. CPU退出到根模式的内核态之后,KVM会判断退出原因,如果是PML Buffer满引起的退出,会将PML Buffer的内容保存下来,然后PML Buffer的索引PML index会被重新置为511。
d. PML Buffer的内容,就是CPU最近写过的内存页地址,它就是内存的脏数据,对于内存迁移来说,该数据可以用来评估虚机的内存变化量。如果PML Buffer中内容较少,那么Qemu可以将虚机暂停然后一次性拷贝完。
e. 当CPU不想记录内存脏页,迁移已经完成后,就可以关闭PML特性。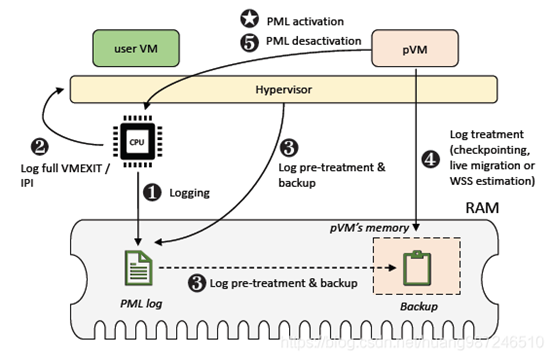
qemu ram脏页位图管理
qemu接收HMP CMD:hmp_migrate, 如下图左上角的调用流程是基于tcp socket的migrate发送过程,创建migation_thread, 在SRC端发起precopy,层层调用到kvm KVG_GET_DIRTY_LOG,进入kernel mode之后,会调用vmx_flush_log_dirty,发生VM_ENTRY进入Guest OS mode,在Guest OS里log sync相关cache dirty page,cpu state等,下一次VM_EXIT会把该dirty log拷贝到user space供qemu 进程进行migration。(这里针对 intel VT-X技术)。
qemu 通过sync_dirty_bitmap 同步脏页到用户态,qemu使用KVMSlot用来跟kvm注册ram,每个ramslot都会分配dirty_bmap用来同步kvm的位图, 通过cpu_physical_memory_set_dirty_lebitmap将位图存到qemu ramlist dirty_memory里,qemu的脏页追踪分成migration, memory code, vga 三种场景分别管理,对于迁移来说只需要关注Dirty_memory_migration 即可。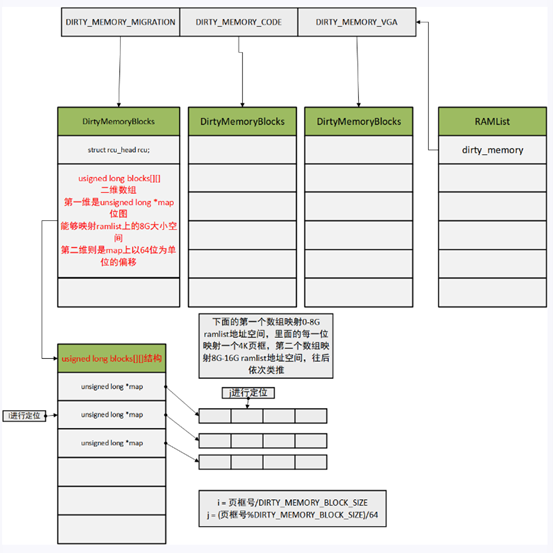
对于迭代迁移流程,每次迭代将首先计算传输的脏页数量,对应到内存ram_save_pending,关键步骤就是发起log_sync同步操作将脏页同步到qemu的ramlist dirty_memory结构里,然后再通过cpu_physical_memory_sync_dirty_bitmap 将ramlist dirty_memory 的位图同步到ramblock 的bmap中, bmap这个位图是用来迁移内存脏页的。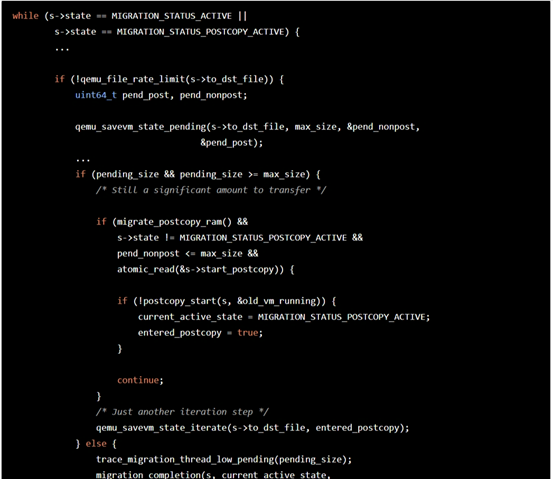
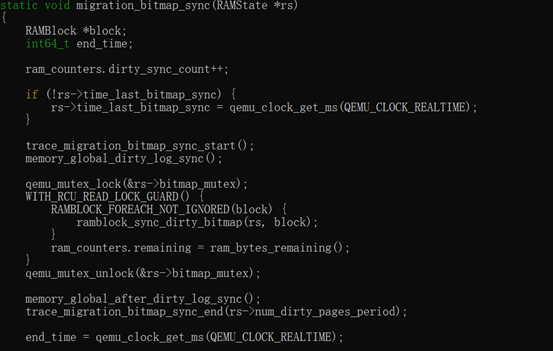
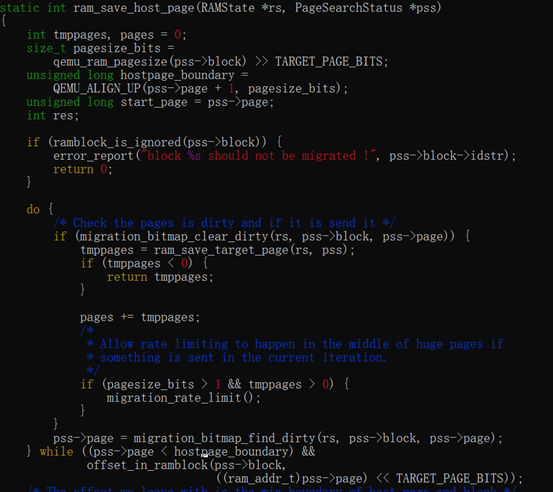
完成脏页同步之后,如果需要传输的脏页时间超过downtime,需要继续迭代,否则迭代结束进入停机拷贝阶段。内存传输脏页ram_find_and_save_block根据ramblock 的bmap找脏页然后进行传输。在ram_save_host_page中先将kvm脏页位图清空的同时将ramblock 的bmap清零,然后再传输脏页内存。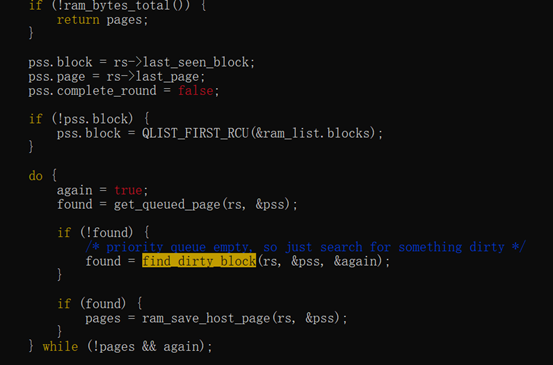
热迁移优化点
- autoconverge
根据脏页产生的速率自动降低vcpu的使用率,增加vcpu睡眠时间,使得vcpu cpu产生的脏页变少,从而减少downtime时间和迁移时间,这个方法目前是使用最广泛的优化迁移的办法,该办法缺点就是在内存脏页速率比较大的情况下可能无法收敛。 - postcopy
相较之前的办法,postcopy解决了虚机脏页速率大的情况下无法收敛的问题,先将cpu和内存初始状态等迁移过去,再目的端跑起来之后根据缺页情况从源端拉取内存,这种办法对虚机性能存在较大影响。 - dirtylimit
利用硬件特性测量vcpu的脏页速率,结合目标速率对vcpu进行限速,方法跟autoconverge类似,目前限速比较低,对于脏页速率较大的场景内存迁移收敛速度快。 - compress/XBZRLE
使用压缩或者对内存内容进行特殊编码,减少内存的传输量,从而加速迁移过程,同时压缩跟解压缩跟特定的硬件结合也是一个可以挖掘的地方。 - multifd
相对于传统的传输方式,用多个channel来传输内容从而加快迁移速度,对于带宽没有限制的场景可能会存在优势。 - rdma
使用rdma作为迁移的数据传输通道,加速迁移。
参考
虚拟化在线迁移优化实践(一):KVM虚拟化跨机迁移原理 - 知乎