dpvs 数据流分析
dpvs ingress 流程分析
从 lcore_job_recv_fwd 开始,这个是 dpvs 收取报文的开始
设备层
dev->flag & NETIF_PORT_FLAG_FORWARD2KNI —> 则拷贝一份 mbuf 到 kni 队列中,这个由命令行和配置文件决定(做流量镜像,用于抓包)
eth 层
netif_rcv_mbuf 这里面涉及到 vlan 的部分不做过多解析
不支持的协议
目前 dpvs 支持的协议为 ipv4, ipv6, arp。 其它报文类型直接丢给内核。其他类型可以看 eth_types。 to_kni
RTE_ARP_OP_REPLY
复制 nworks-1 份 mbuf,发送到其它 worker 的 arpring 上 ( **_to_other_worker** ), 这份报文 fwd 到arp 协议.
RTE_ARP_OP_REQUEST
这份报文 fwd 到arp 协议.
arp 协议
arp 协议处理 neigh_resolve_input
RTE_ARP_OP_REPLY
建立邻居表,记录信息,并且把这个报文送给内核。to_kni
RTE_ARP_OP_REQUEST
无条件返回网卡的 ip 以及 mac 地址 (free arp), netif_xmit 发送到 core_tx_queue
其它 op_code
drop
ip 层
ipv4 协议 (ipv6 数据流程上一致)
ipv4_rcv
ETH_PKT_OTHERHOST
报文的 dmac 不是自己,drop
ipv4 协议校验
不通过, drop
下一层协议为 IPPROTO_OSPF
INET_HOOK_PRE_ROUTING hook
hooklist: _dp_vs_in , dp_vs_prerouting
这两个都与 synproxy 有关系,但是我们不会启用这个代理,不过需要注意的是 syncproxy 不通过时会丢包 drop
dp_vs_in
非 ETHPKT_HOST(broadcast 或者 multicast 报文)或 ip 报文交给 _ipv4_rcv_fin 处理
非 udp, tcp, icmp, icmp6 报文交给 ipv4_rcv_fin 处理
分片报文, 黑名单地址报文 drop
非本 core 报文, redirect到对应 core 上
conn 超时,drop
xmit_inbound
接收速率限速 drop
这条连接的发送函数没有定义,走 ipv4_rcv_fin
定义的发送函数: dp_vs_xmit_nat,dp_vs_xmit_tunnel, dp_vs_xmit_dr, dp_vs_xmit_fnat, dp_vs_xmit_snat
其它的包发送到 core_tx_queue
xmit_outbound
发送速率限速 drop
这条连接的发送函数没有定义,走 ipv4_rcv_fin
定义的发送函数: dp_vs_out_xmit_nat, dp_vs_out_xmit_fnat, dp_vs_out_xmit_snat
其它的包发送到 core_tx_queue
ipv4_rcv_fin 和内核处理流程基本一致
ipv4_local_in 是发给自己的报文
ipv4_forward 走路由
ipv4_local_out
- INET_HOOK_LOCAL_OUT hook_list: none
- to ipv4_output
ipv4_output
- INET_HOOK_POST_ROUTING hook_list: none
- to ipv4_output_fin
ipv4_output_fin
- ip 报文分片,失败会drop*
- to ipv4_output_fin2
ipv4_output_fin2
查找路由,mbuf 发送到 core_tx_queue
dpvs_egress 报文分析
也就是 core_tx_queue 的数据流向,从netif_tx_burst开始分析。这里 mbuf 中的内容都已经填充完成,调用了 rte_eth_tx_burst,发送至网卡。
dpvs_redirect 分析
dp_vs_redirect_ring_proc, 从 dp_vs_redirect_ring[cid][peer_id]中获取数据报文,导向 dpvs_ingress
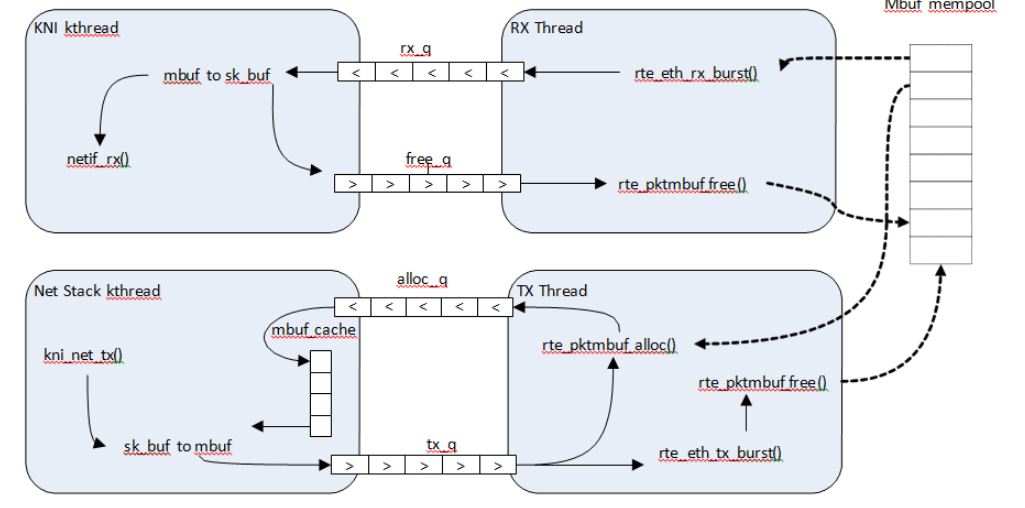
dpvs_kni
入口函数: kni_lcore_loop
- kni_ingress_flow_process: kni 接管的队列的所有包都往kernel_kni_in上送 (非 master core)
- lcore_job_xmit: 发送 kni_core 上的网络包(非 master core),core_tx_queue
dpvs 内部 kni 队列的处理如下两个流程。
dpvs_kni_ingress
kni_ingress_process:
- rte_ring_dequeue_burst(dev->kni.rx_ring): 收取所有 dev 上的 kni 报文接收队列的报文
- rte_kni_tx_burst: 发送到kernel_kni_in
dpvs_kni_egress
kni_egress_process:
- rte_kni_handle_request: 分配 mbuf 给 kni.resp_q
- rte_kni_rx_burst(dev->kni.kni): 接收 kni 设备中的报文,kernel_kni_out
- netif_xmit: 发送到对应 worker 的发送队列,core_tx_queue
kni 设备
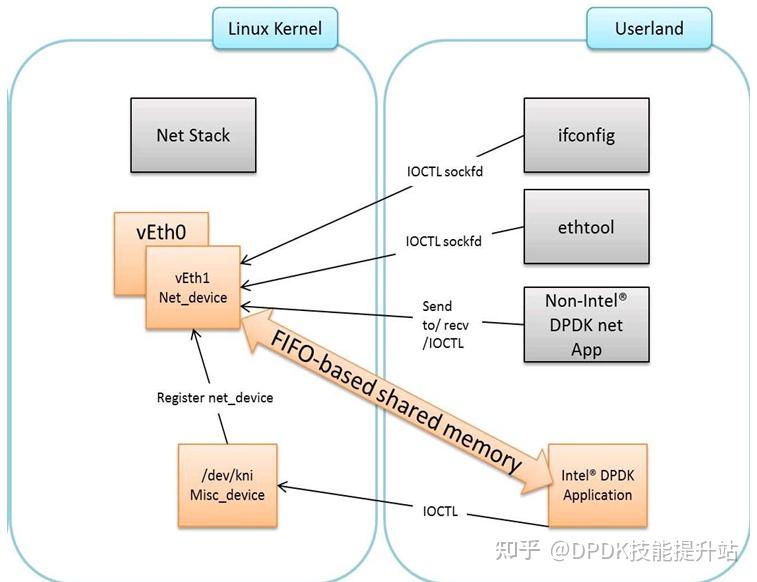
kni_init
- rte_kni_alloc 用户态 kni 设备申请
kernel/linux/kni_misc.c
用于管理 kni 设备的。 简单的来说,这个文件创建了一个 kni_misc 设备,提供了 ioctl 方法创建相应的队列,可以简单的来看下 ioctl 的实现。
1 | kni_ioctl: |
kernel/linux/kni_net.c
实际的 kni_net 设备,实现了报文的收发
kni_net_init
1 | kni_net_init |
kernel_kni_ingress
1 | kni_net_rx |
kernel_kni_egress
内核发送给 kni_thread, 对于内核来说最终调用 kni_net_tx 函数
1 | kni_net_tx |
用户态网卡驱动
igb_uio, mnlx cx5 等物理网卡
- rte_eth_tx_burst
- rte_eth_rx_burst
kni
- rte_kni_tx_burst(struct rte_kni *kni, struct rte_mbuf **mbufs, unsigned int num)
1 | num = RTE_MIN(kni_fifo_free_count(kni->rx_q), num); |
- rte_kni_rx_burst(struct rte_kni *kni, struct rte_mbuf **mbufs, unsigned int num)
1 | unsigned int ret = kni_fifo_get(kni->tx_q, (void **)mbufs, num); |