摘自
eBPF 用户空间虚拟机实现相关 | Blog (forsworns.github.io)
[译] Cilium:BPF 和 XDP 参考指南(2021) (arthurchiao.art)
hook point
可以插入 bpf 代码的位置
1 | enum bpf_prog_type { |
程序类型
| bpf_prog_type | BPF prog 入口参数(R1) | 程序类型 |
|---|---|---|
| BPF_PROG_TYPE_SOCKET_FILTER | struct __sk_buff | 用于过滤进出口网络报文,功能上和 cBPF 类似。 |
| BPF_PROG_TYPE_KPROBE | struct pt_regs | 用于 kprobe 功能的 BPF 代码。 |
| BPF_PROG_TYPE_TRACEPOINT | 这类 BPF 的参数比较特殊,根据 tracepoint 位置的不同而不同。 | 用于在各个 tracepoint 节点运行。 |
| BPF_PROG_TYPE_XDP | struct xdp_md | 用于控制 XDP(eXtreme Data Path)的 BPF 代码。 |
| BPF_PROG_TYPE_PERF_EVENT | struct bpf_perf_event_data | 用于定义 perf event 发生时回调的 BPF 代码。 |
| BPF_PROG_TYPE_CGROUP_SKB | struct __sk_buff | 用于在 network cgroup 中运行的 BPF 代码。功能上和 Socket_Filter 近似。具体用法可以参考范例 test_cgrp2_attach。 |
| BPF_PROG_TYPE_CGROUP_SOCK | struct bpf_sock | 另一个用于在 network cgroup 中运行的 BPF 代码,范例 test_cgrp2_sock2 中就展示了一个利用 BPF 来控制 host 和 netns 间通信的例子。 |
BPF 程序类型就是由 BPF side 的代码的函数参数确定的,比如写了一个函数,参数是 struct __sk_buff 类型的,它就是一个 BPF_PROG_TYPE_SOCKET_FILTER 类型的 BPF 程序
XDP
express datapath
是一个 bpf hook 点,位于网络驱动收包的最开始,协议栈还没有提取出包的 metadata,因此适合做包过滤,例如 DDOS 防护。cillium 的 prefilter 在此处实现
tc ingress/egress
三层协议栈之前的 hook 点,报文经过了一些初始处理。适合做本地收包处理,比如 l3/l4 策略或者转发。tc hook 可以与 xdp hook 进行结合,经过这两层过滤后可以认定大部分报文都是合法的且可以发给 host
容器场景下一般用的 veth pair,需要将 bpf 程序挂到 host 侧的 veth 的 tc ingress hook 上。再配合上 host 业务网卡的 bpf 程序,可以实现 host 级别和容器级别的 policy

socket operations
绑在 root cgroup 上监听 tcp 状态
Socket send/recv
监听 send/recv 系统调用,可以查看 message 并根据 message 执行丢弃或转发动作
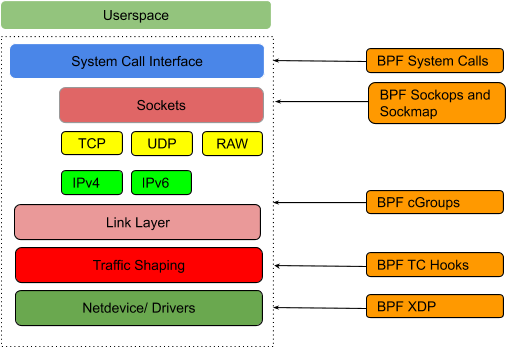
bgp 架构
bpf 提供了:
- RISC 指令集 (一套虚拟机)
- kv 存储的 map
- 与内核交互的 helper functions
- 调用其他 bpf 程序的接口
- 一个虚拟的文件系统,用来加载网卡,程序以及上述的 map
bpf 程序的编译后端是 llvm,因此用 c 编译 bpf 程序需要用 clang 编译成 llvm 中间代码。加载 bfp 程序后,内核即时编译器会动态生成 opcodes,实现指令注入的效果。即使注入指令有以下优点:
- 报文不需要内核态用户态的切换
- 根据业务场景需求灵活修改数据面代码
- 更新程序不需要重启内核
- 多平台兼容,不需要第三方模块
- 复用内核的资源(驱动,协议栈等),但由于程序经过内核校验,不会将内核搞崩
代码模型是事件驱动模型。例如报文处理的 bpd 程序在收包时被唤醒,kprobe 程序在代码调用到某个系统调用地址时被唤醒
指令集与寄存器
11 个 64 位寄存器(r0~r10),一个 PC,512 个字节的栈空间
r0 存放函数的返回值,也可以存放 bpf 程序的退出值
r1-r5 是临时寄存器,可以泄露到 bpf 栈中,也可以用来存放 helper functions 的入参。泄露 spilling 指的是寄存器的值移动到 bpf 栈中,填充 filling 指的是 bpf 栈中的数据移动至寄存器中。其中 r1 指向上下文,例如包处理时指向 skb。这么做的原因是由于限制了寄存器数量,寄存器不够用
r6-r9 是 callee 函数用的通用寄存器
r10 存放 FP,只读
每个 bpf 程序限制 4096 条指令,5.1 版本内核限制 100 万条指令。虽然指令集支持 jumps 指令,但是内核校验器不允许循环,且跳到另一个 bpf 程序的限制为 33 次,因此代码需要展开循环
指令集中所有指令的长度固定为 64bit,目前共实现了 87 条指令。指令有大端小端的区分,由 linux/bpf.h 定义
eBPF Instruction Set — The Linux Kernel documentation
| 32 bits (MSB) | 16 bits | 4 bits | 4 bits | 8 bits (LSB) |
|---|---|---|---|---|
| immediate | offset | source register | destination register | opcode |
与通用的指令集一样,bpf 指令的 opcode 也分为 load/save(LD,ST),process(alu)和 branch(jmp)。opcode 字段的地 3 位决定了指令类型(cbpf,ebpf),目前大部分架构的内核 eBPF JIT 编译器支持自动将 cbpf 指令转为 ebpf
helper functions
提供了与内核的接口,retrieve / push data from / to the kernel。可用的 helper function 取决于 bpf 程序锁挂载的位置。挂到 socket 层可用的 helper 是挂到 tc 层可用的 helper 的一个子集
格式统一
1 | u64 fn(u64 r1, u64 r2, u64 r3, u64 r4, u64 r5) |
只能调用内核支持的 helper 函数。内核将 helper 抽象成以下的宏,目的是为了与 cBPF 兼容
BPF_CALL_0() to BPF_CALL_5()
Maps
高性能 kv 存储,可以作为多个 bpf 程序的共享全局变量,用户态程序使用 fd 访问。分为通用 map 和非通用 map。关于 map 的种类和用法参考
BPF 进阶笔记(二):BPF Map 类型详解:使用场景、程序示例 (arthurchiao.art)
代码中 map 的初始化
1 | struct { |
object pinining
内核中的 bpf 程序,bpf map 只能通过文件描述符或 inode 的方式传递到用户态。bpf 程序和 bpf map 可以绑定到虚拟文件系统里/sys/fs/bpf/, 从而实现多个 bpf 程序共享 bpf map
tail call
只允许相同类型的 bpf 程序进行尾调用。调用后不会返回到原来函数,不改变栈顶指针,直接复用相同的栈帧。x86 的 5.10 版本内核才支持尾调用和普通调用混合使用。
1 |
|
使用方法:
- 由于不能使用全局变量,定义一个 BPF_MAP_TYPE_PROG_ARRAY 用来注册尾调用函数
- 给尾调用函数打标记:
__section(__stringify(ID) "/" #KEY - 传入同类型 bpf 程序的参数(skb),注册的 map,调用函数的 key
tail_call(skb, &jmp_map, 0);